Будем ломать веб-сервер и закидывать его пачками HTTP запросов. Потихоньку заполнять всё вокруг HTTP-флудом и наблюдать полнейшую деградацию. Готовься Azure, будет не до смеха!
Если чуть серьёзнее, то выполняя стандартные лабы по знакомству с Azure в рамках AZ-900 Microsoft Azure Fundamentals решил посмотреть на что способна одна из минимальных конфигураций виртуальных машин Standard B1s (1 GiB RAM, 1 vCPU).
В стандартных лабах на виртуалку ставится веб-сервер вроде Apache или IIS, запускается простенький сайт и на этом всё заканчивается. Мне показалось такого знакомства мало и стало интересно посмотреть, как сервер будет реагировать на большое количество запросов, что станется с временем ответа и, главное, поможет ли изменения размера виртуалки улучшить качество работы. Кроме того, чтобы добавить серверу забот, на виртуалке с Ubuntu был поднят WordPress (Apache, MySQL, PHP). Для теста использовался скрипт на Python, который непрерывно генерил GET запросы на один и тот же адрес.
В случае с одиночными запросами время ответа сервера не превышало 300-400 мс, что для такой конфигурации выглядело вполне приемлемым.
Другое дело, как сервер будет реагировать на массовые запросы, когда GET прилетают пачками. На Python такие параллельные запросы можно реализовать используя модуль “concurrent.futures”, который дает доступ к высокоуровневому интерфейсу для асинхронных вызовов. Идея реализации была вдохновлена ресурсом creativedata.stream. В итоге, для теста сервер был атакован волной GET запросов с линейно возрастающим количеством одновременных запросов. Для большей наглядности время ожидания ответа на каждый запрос было ограничено 10 секундами. Для каждой попытки отправлялось 5000 запросов. Для каждой попытки отправлялось 5000 запросов. Между попытками таймаут 3 минуты.
Результаты теста для VM Standard B1s приведены в таблице
|
Кол-во параллельных GET запросов |
Время теста (с) | Среднее время ответа (с) | Максимальное время ответа (с) |
Количество отказов |
| 10 | 246 | 0.482504 | 1.393406 | 0 |
| 20 | 183 | 0.716227 | 1.775027 | 0 |
| 30 | 158 | 0.925803 | 2.239563 | 0 |
| 40 | 133 | 1.028995 | 10.389413 | 4773 |
После попытки с 40 одновременными запросами стало ясно, что сервер не справляется, и количество ответов отличных от “200” начало приближаться к 100%.
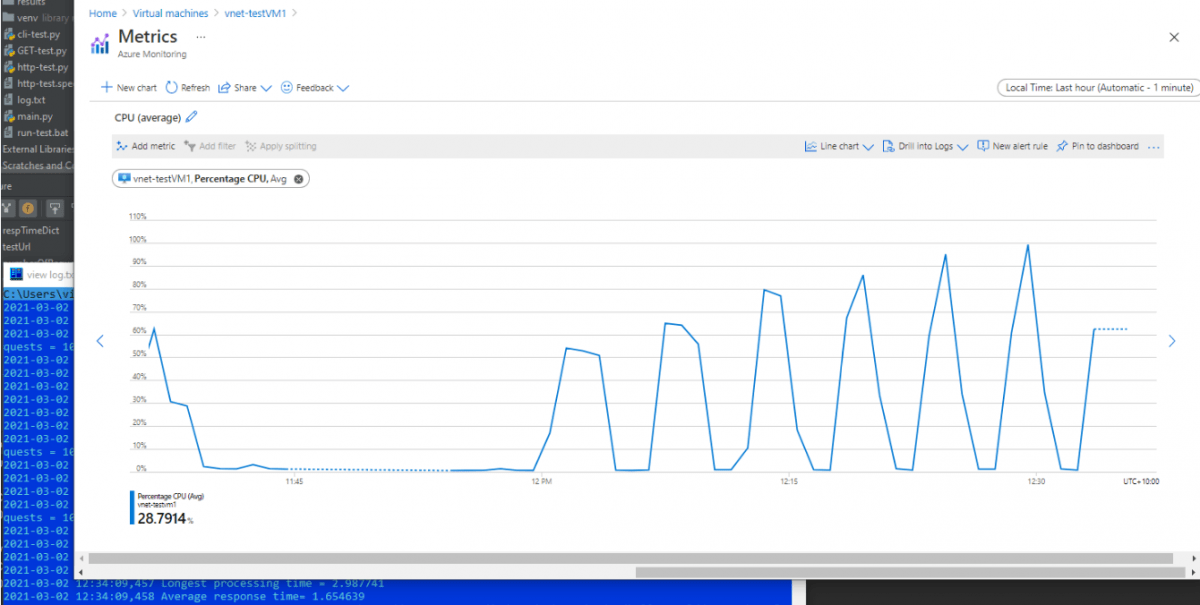
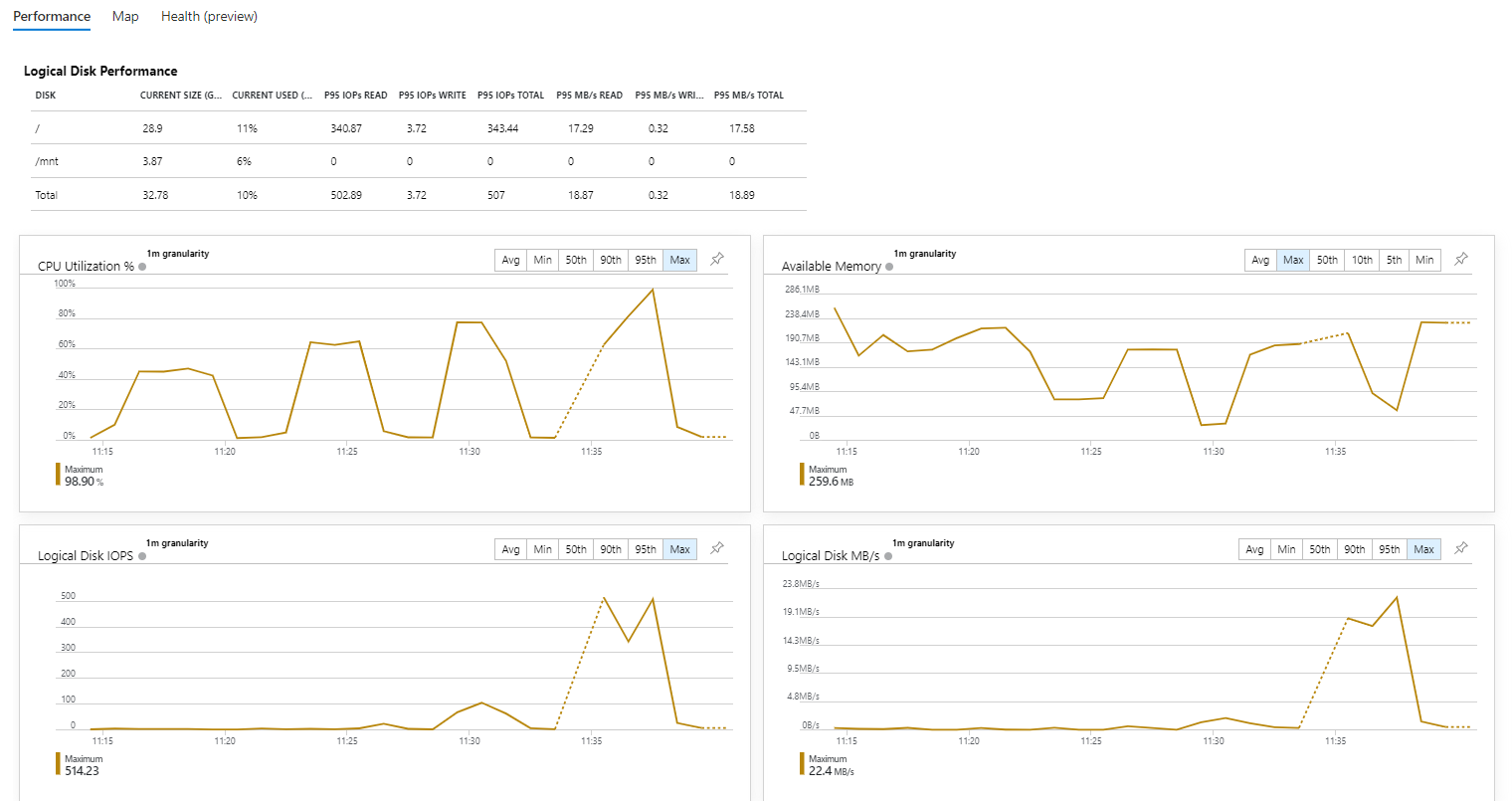
Давайте взглянем на графики производительности виртуальной машины. Загрузка ЦПУ прямо пропорциональна интенсивности тестовой нагрузки. Оперативная память также не пролазит в бутылочное горлышко.
Как поведёт себя сервер, после изменения размера виртуальной машины. Пара кликов и B1s превращается в Standard B2s (4GiB RAM, 2 vCPU). Получится ли от двух ЦПУ получить двухкратный прирост?
Повторяем тест, но чуть увеличиваем шаг. Количество запросов в каждой попытке устанавливаем в 10000.
Результаты теста для VM Standard B2s приведены в таблице
|
Кол-во параллельных GET запросов |
Время теста (с) | Среднее время ответа (с) | Максимальное время ответа (с) |
Количество отказов |
| 20 | 198 | 0.387310 | 1.377070 | 0 |
| 40 | 171 | 0.660414 | 1.481950 | 0 |
| 60 | 140 | 0.808657 | 1.674038 | 0 |
| 80 | 130 | 1.001915 | 2.142157 | 0 |
| 100 | 119 | 1.163476 | 2.252231 | 0 |
| 120 | 119 | 1.417223 | 2.703418 | 0 |
| 140 | 119 | 1.654639 | 2.98774 | 0 |
| 160 | 119 | 1.901040 | 5.622294 | 0 |
Как и в первом тесте график загрузки ЦПУ и использования памяти прямо пропорционален количеству одновременных запросов. Однако, полнейшей деградации сервиса добиться не удалось. Хоть и с двух секундным таймаутом, но сервер иправно отвечал на все запросы.
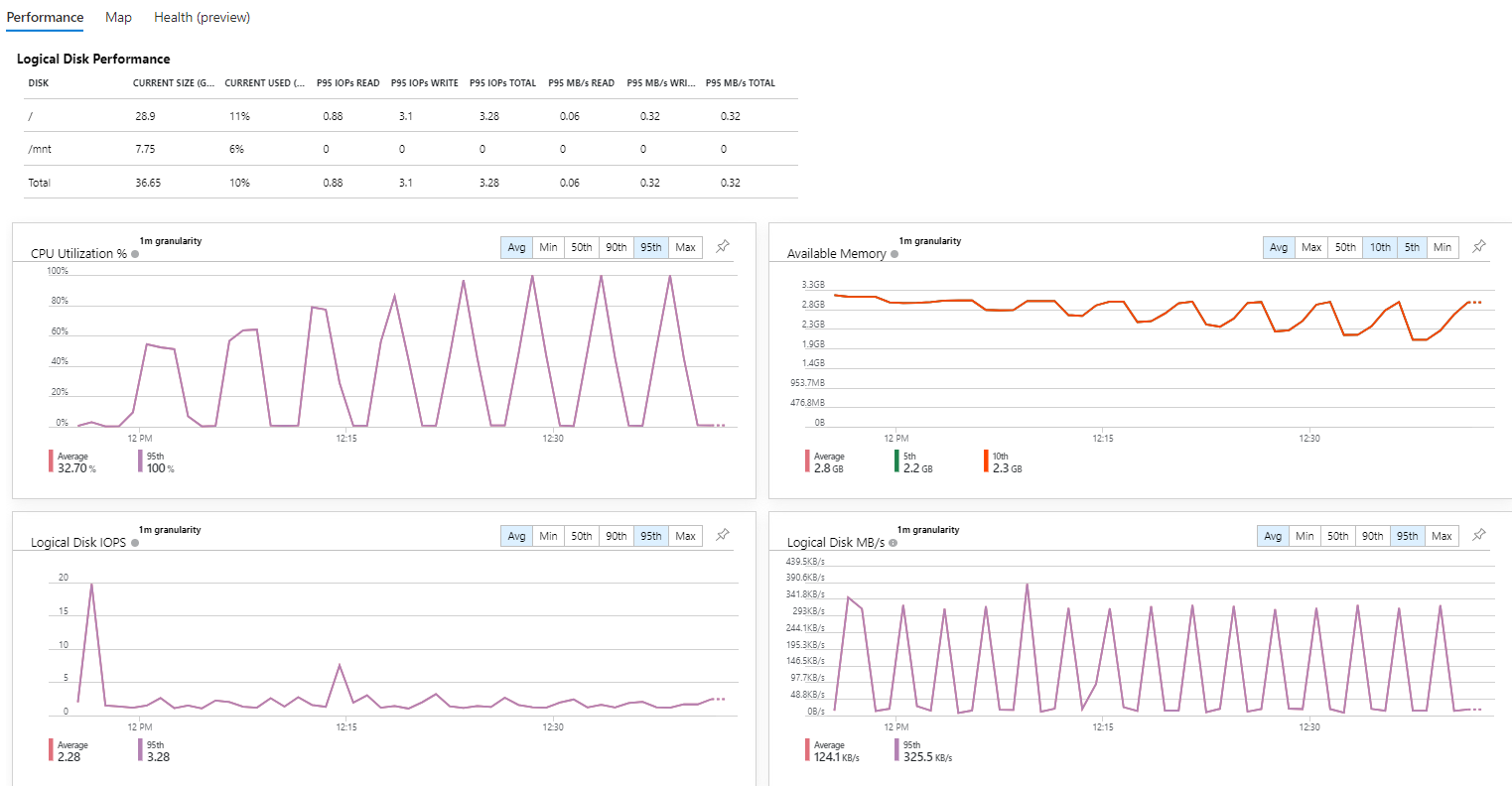
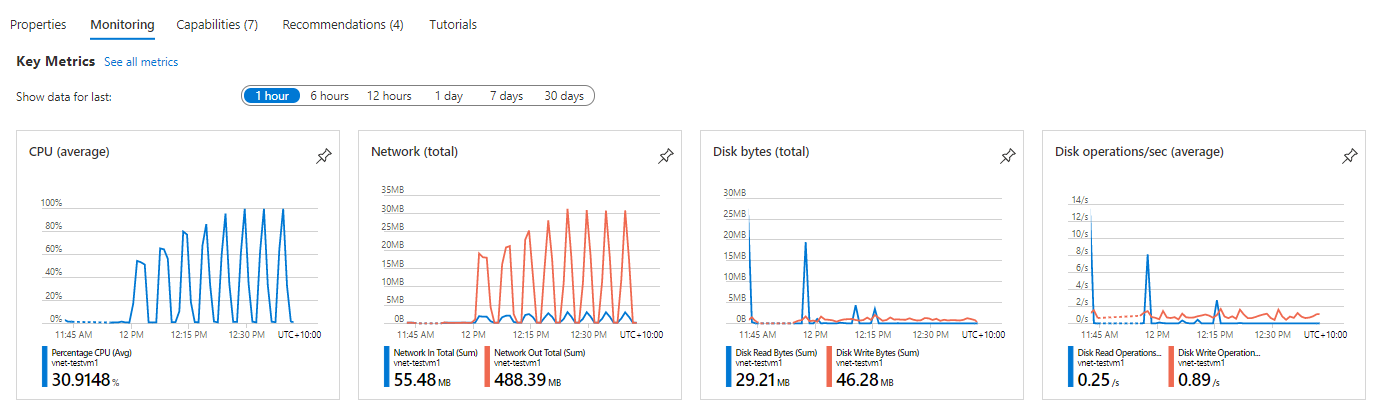
При 160 одновременных запросах нагрузка на сеть уже со стороны тестовой утилиты достигала 5Mb/s и дальнейшее увеличение количества одновременных запросов было решено не проводить.
Место для выводов
Данный тест с HTTP-флудом и текущей реализацией не претендуют на покорение космоса и следование золотым стандартам. Однако, тесты продемонстрировали ожидаемую прямую зависимость между количеством одновременных запросов и загрузкой на ЦПУ, память и средним и максимальным временем ответа.
Судя по всему, сервер с большим объемом оперативной памяти (4Gb против 1Gb) справляется с такого рода нагрузкой лучше и даже при 5-ти кратном увеличением количества запросов (160 против 30) исправно отвечает 200 ОК!
PS
Пример тествой утилиты доступен в моём репозитории на github
Эта же статья на Хабре